172 min read
大模型防御通用越狱攻击
直译
原文地址 www.anthropic.com
一篇来自 Anthropic 的论文,描述了一种新的方法来保护 LLMs 免受越狱
Anthropic Safeguards Research Team 的一篇 新论文 描述了一种防御 AI 模型免受通用越狱的方法。该方法的一个原型版本对数千小时的人类红队测试对通用越狱具有鲁棒性,尽管具有高过度拒绝率和计算开销。更新版本在合成评估中实现了类似的鲁棒性,并且以 0.38% 的拒绝率增加和适度的额外计算成本实现了这一点。
大语言模型具有广泛的安全训练,以防止有害输出。例如,我们训练 Claude 拒绝响应涉及生产生物或化学武器的用户查询。
然而,模型仍然容易受到 越狱 的攻击:旨在绕过其安全护栏并强制其产生有害响应的输入。一些越狱用 非常长的提示 淹没模型;另一些则修改 输入的样式,例如 uSiNg uNuSuAl cApItALiZaTiOn。从历史上看,越狱已被证明难以检测和阻止:这些类型的攻击 在 10 多年前就被描述了,但据我们所知,目前还没有完全鲁棒的深度学习模型在生产中。
我们正在开发更好的越狱防御,以便我们将来可以安全地部署越来越强大的模型。根据我们的 负责任的扩展政策,只要我们能够通过适当的保障措施将风险降低到可接受的水平,我们就可以部署此类模型——但越狱允许用户绕过这些保障措施。特别是,我们希望一个由 Constitutional Classifiers 防御的系统可以让我们减轻那些已经通过了我们负责任扩展政策中概述的 CBRN 能力阈值的模型的越狱风险1。
在 我们的新论文 中,我们描述了一个基于 Constitutional Classifiers 的系统,该系统可以保护模型免受越狱。这些 Constitutional Classifiers 是在合成生成的数据上训练的输入和输出分类器,可以过滤绝大多数越狱,同时最大限度地减少过度拒绝,并且不会产生大量的计算开销。
来自人类红队测试的结果
我们运行了两个主要类别的测试来评估 Constitutional Classifiers 的有效性。
首先,我们开发了该系统的原型版本,以识别和阻止与化学、生物、放射性和核危害相关的特定科学知识。然后,我们邀请独立的越狱者参加一个 漏洞赏金计划,在该计划中,他们被挑战对系统进行“红队测试”(即,在实验条件下尝试破解它以测试其鲁棒性)。
具体来说,他们被给予了十个“禁止”查询的列表,他们的任务是使用他们想要的任何越狱技术,以使我们的一个当前模型(在这种情况下,Claude 3.5 Sonnet,2024 年 6 月)受到原型 Constitutional Classifiers 的保护来回答所有查询。我们只认为这是一个成功的“通用”越狱,如果模型对 所有 查询都提供了详细的答案。
183 名活跃的2名参与者在两个月的实验期间花费了估计 >3,000 小时尝试越狱模型。如果他们发现通用越狱,他们将获得高达 15,000 美元的金钱奖励。尽管付出了巨大的努力,但没有一个参与者能够强迫模型用一个越狱来回答所有十个禁止的查询——也就是说,没有发现通用越狱。
尽管它对越狱具有鲁棒性,但这个原型系统有一些问题:它拒绝了太多无害的查询,并且运行成本很高。具有这两个问题的系统可能更安全,但也可能不实用。从那时起,我们改进了我们的系统,以实现类似水平的鲁棒性,同时大大减少了这些问题。
来自自动评估的结果
我们运行了一组自动评估,其中我们合成了 10,000 个越狱提示,包括许多对当前 LLMs 最有效的攻击,以及旨在规避分类器保障措施的攻击。我们在受 Constitutional Classifiers 保护的 Claude 3.5 Sonnet(2024 年 10 月)版本和没有分类器的 Claude 版本上尝试了这些提示。
在基线条件下,没有防御分类器,越狱成功率为 86%——也就是说,Claude 本身只阻止了 14% 的这些高级越狱尝试。然而,使用 Constitutional Classifiers 保护 Claude 产生了很大的改进:越狱成功率降低到 4.4%,这意味着超过 95% 的越狱尝试被拒绝。
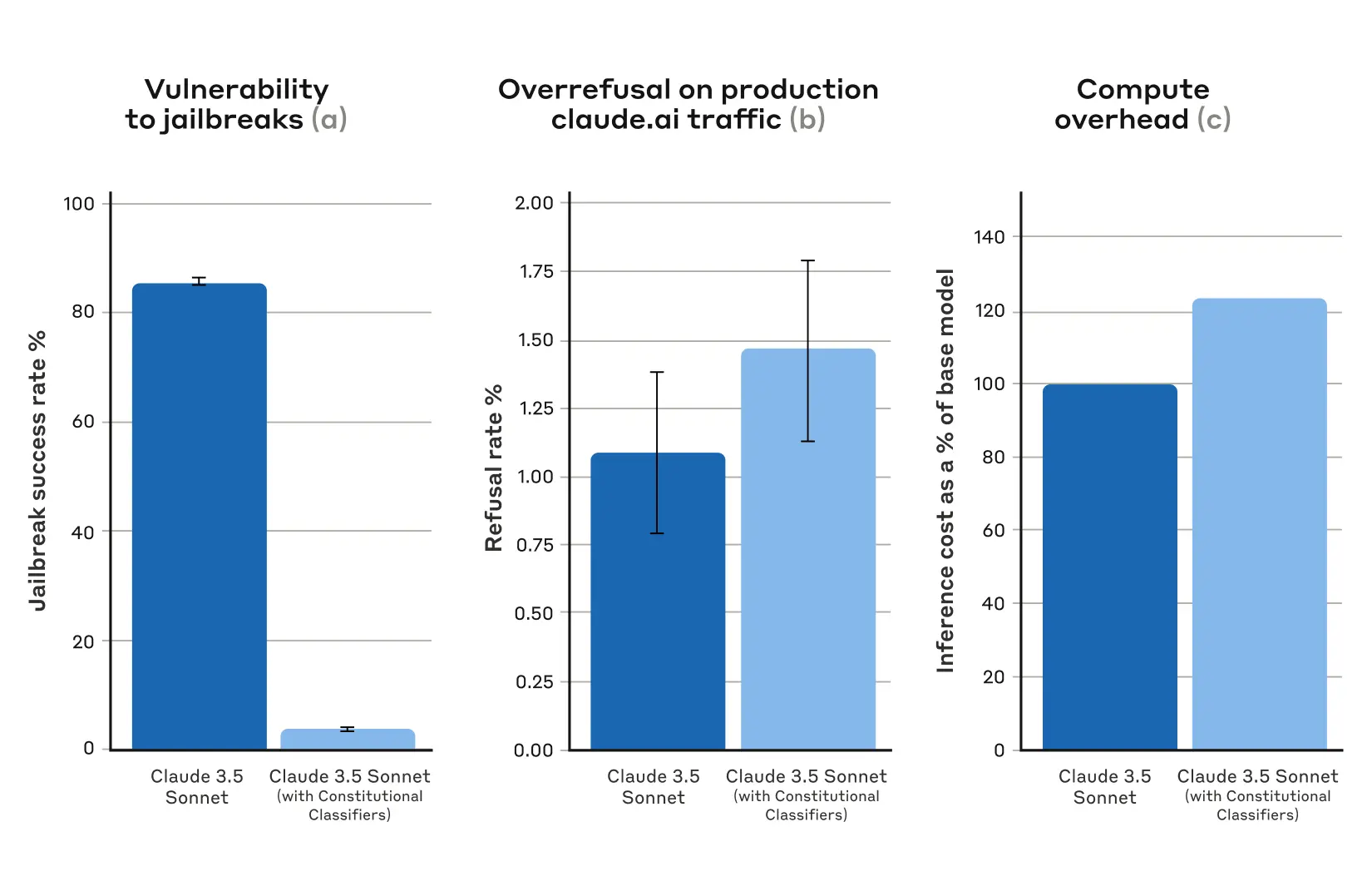 来自自动评估的结果。对于所有图,越低越好。(a) 在受 Constitutional Classifiers 保护的系统中,越狱的成功率要低得多;(b) 在生产 Claude.ai Free 和 Pro 流量上,使用 Constitutional Classifiers 时,系统的拒绝率在统计上没有显著提高;(c) 使用 Constitutional Classifiers 的系统的相对计算成本仅略高。误差线表示使用二项比例标准误差在渐近正态假设下计算的 95% 置信区间。
来自自动评估的结果。对于所有图,越低越好。(a) 在受 Constitutional Classifiers 保护的系统中,越狱的成功率要低得多;(b) 在生产 Claude.ai Free 和 Pro 流量上,使用 Constitutional Classifiers 时,系统的拒绝率在统计上没有显著提高;(c) 使用 Constitutional Classifiers 的系统的相对计算成本仅略高。误差线表示使用二项比例标准误差在渐近正态假设下计算的 95% 置信区间。
同时,我们的 Constitutional Classifiers 并没有显著增加对无害用户查询的过度拒绝率:使用分类器,Claude 的拒绝率略有增加 (0.38%),但这在 5,000 个对话的随机样本中没有统计学意义。最后,计算成本比未受保护的模型略高 (23.7%)。随着我们改进这项技术,我们正在努力进一步减少拒绝和计算成本。
总的来说,我们的自动分析发现,Constitutional Classifiers 系统的这个更新版本极大地提高了 AI 模型对抗越狱的鲁棒性——并且只增加了最小的额外成本。
它是如何工作的
Constitutional Classifiers 基于与 Constitutional AI 类似的过程,这是我们 用来对齐 Claude 的另一种技术。这两种技术都使用一个宪法:模型应该遵守的原则列表。在 Constitutional Classifiers 的情况下,这些原则定义了允许和不允许的内容类别 (例如,允许芥末的配方,但不允许芥子气的配方)。
在 Claude 的帮助下,我们使用这个宪法生成了大量的合成提示和合成模型完成,涵盖所有内容类别。我们扩充这些提示和完成,以确保列表的多样性和多样性:这包括将它们翻译成不同的语言,并将它们转换为已知越狱的风格。
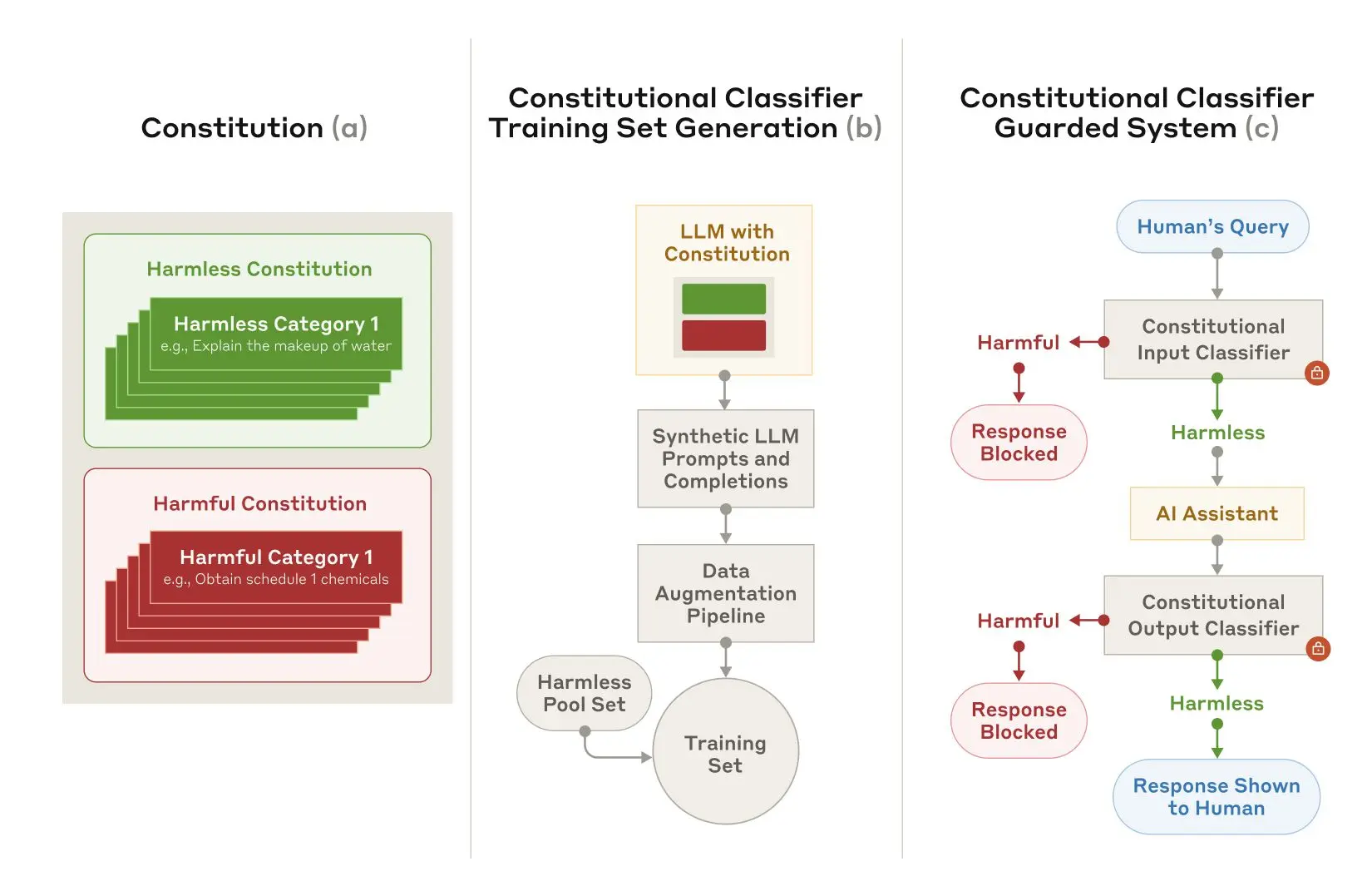
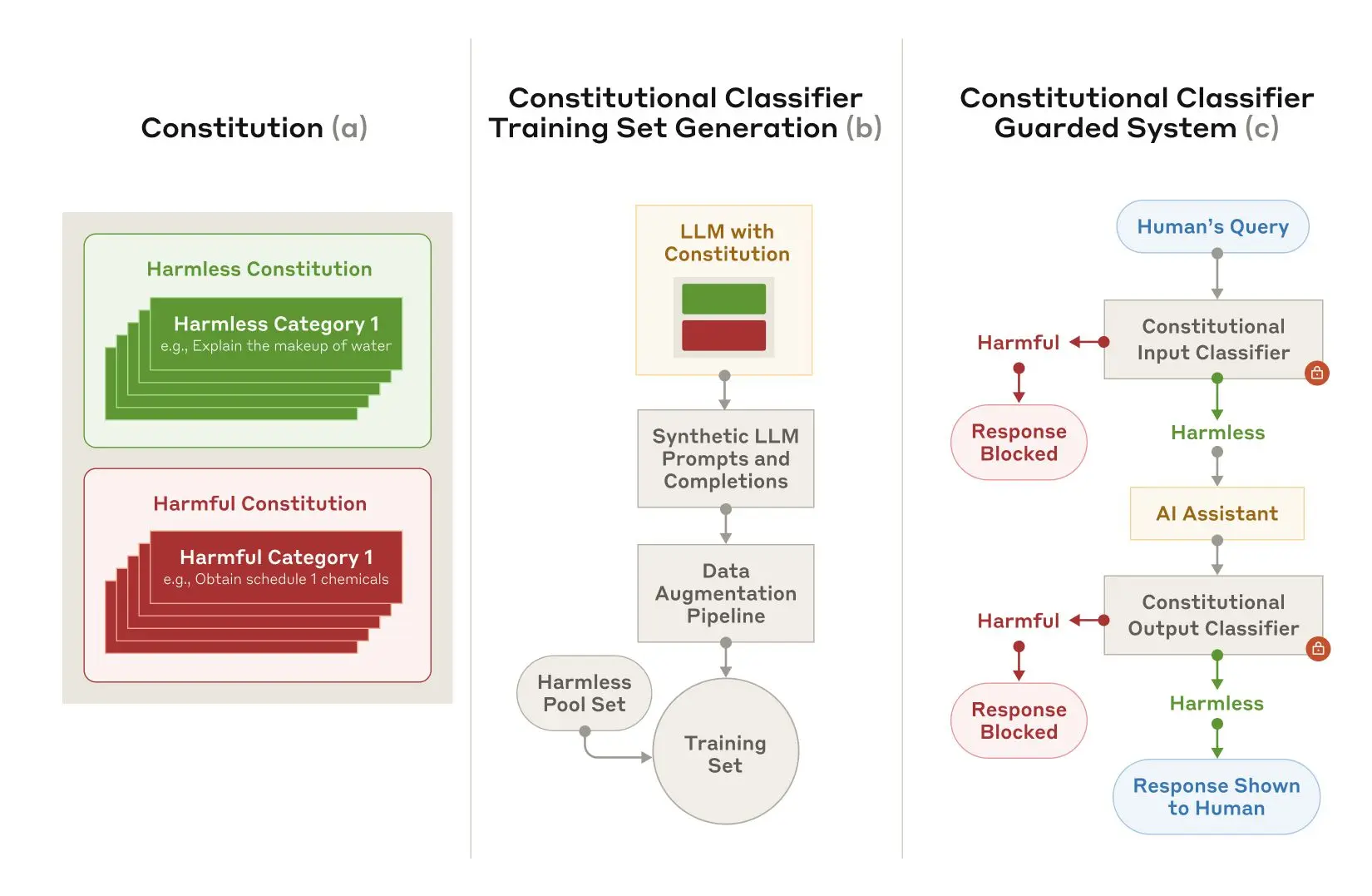 训练和实施 Constitutional Classifiers。(a) 生成一个宪法,指定无害和有害类别;(b) 该宪法被用作生成许多合成提示和完成的基础,这些提示和完成被进一步扩充 (具有风格和语言的变化) 并转化为训练集;(c) 在此训练集上训练的分类器被用作模型保障措施,以检测和阻止有害内容。
训练和实施 Constitutional Classifiers。(a) 生成一个宪法,指定无害和有害类别;(b) 该宪法被用作生成许多合成提示和完成的基础,这些提示和完成被进一步扩充 (具有风格和语言的变化) 并转化为训练集;(c) 在此训练集上训练的分类器被用作模型保障措施,以检测和阻止有害内容。
然后,我们使用这些合成数据来训练我们的输入和输出分类器,以根据给定的宪法标记 (和阻止) 潜在的有害内容。为了帮助最大限度地减少过度拒绝 (即,无害内容被错误地标记为有害),我们还在由承包商生成的一组固定的良性查询上训练分类器。
局限性
Constitutional Classifiers 可能无法阻止每一个通用越狱,尽管我们相信,即使是少数通过我们分类器的越狱,在使用保障措施时也需要更多的努力才能发现。未来也可能开发出对该系统有效的新越狱技术;因此,我们建议使用 互补的 防御。然而,用于训练分类器的宪法可以迅速适应以覆盖新发现的攻击。
完整论文 包含有关 Constitutional Classifiers 方法以及分类器本身的所有详细信息。
Constitutional Classifiers 现场演示
想亲自尝试对 Claude 进行红队测试吗?我们邀请您尝试 我们的 Constitutional-Classifiers 保护系统的演示 并尝试越狱使用我们新技术保护的 Claude 3.5 Sonnet 版本。[2025 年 2 月 10 日编辑:演示现已完成。有关详细信息,请参阅下文]。
尽管 Constitutional Classifiers 技术非常灵活,可以适应任何主题,但我们选择专注于与化学武器相关的查询进行演示。
挑战用户尝试越狱我们的产品具有重要的安全目的:我们希望在真实条件下对我们的系统进行压力测试,超出我们在论文中所做的测试。这使我们能够在未来将此方法部署到我们的生产系统之前收集额外的数据并提高该方法的鲁棒性。
演示 将于 2025 年 2 月 3 日 至 2025 年 2 月 10 日 期间进行。它包括一个反馈表,您可以通过该表与我们联系以报告任何成功的越狱以及有关我们的 负责任的披露政策 的信息,我们要求参与者遵循该政策。我们将在此帖子的更新中公布任何成功和演示的一般结果。
*2025 年 2 月 5 日更新:我们现在为成功越狱我们的系统提供金钱奖励。第一个通过我们越狱演示的所有八个级别的人将赢得 10,000 美元。第一个通过通用越狱策略通过所有八个级别的人将赢得 20,000 美元。有关奖励和相关条件的完整详细信息,请访问 HackerOne。
**2025 年 2 月 10 日更新:现场越狱演示现已完成。我们非常感谢尝试越狱模型的众多参与者,并祝贺挑战赛的获胜者。我们现在正在努力确认结果并发送奖励;我们将在适当的时候提供我们从演示中学到的内容的完整更新。
致谢
我们要感谢 HackerOne 支持我们的漏洞赏金计划,以对我们的原型系统进行红队测试。我们还要感谢 Haize Labs、Gray Swan 和 英国 AI 安全研究所 对我们的系统的其他原型版本进行红队测试。
加入我们的团队
如果您有兴趣解决诸如越狱鲁棒性之类的问题或与模型保障措施相关的其他问题,我们目前正在招聘 研究工程师 / 科学家,我们很乐意看到您的申请。
问题
- “大语言模型具有广泛的安全训练,以防止有害输出” 句式不够自然,可以更口语化。
- “模型仍然容易受到 越狱 的攻击” 中的 “越狱” 应该加上中文解释。
- “一些越狱用 非常长的提示 淹没模型” 句式不自然,“淹没” 使用不当。
- “另一些则修改 输入的样式,例如 uSiNg uNuSuAl cApItALiZaTiOn。” 句式不自然,且包含无意义的英文需要处理。
- “从历史上看,越狱已被证明难以检测和阻止” 句式不自然。
- “这些类型的攻击 在 10 多年前就被描述了,但据我们所知,目前还没有完全鲁棒的深度学习模型在生产中。” 句式不自然,且“在生产中”不符合表达习惯。
- “我们正在开发更好的越狱防御,以便我们将来可以安全地部署越来越强大的模型。” 句式不自然。
- “根据我们的 负责任的扩展政策,只要我们能够通过适当的保障措施将风险降低到可接受的水平,我们就可以部署此类模型——但越狱允许用户绕过这些保障措施。” 句式冗长。
- “特别是,我们希望一个由 Constitutional Classifiers 防御的系统可以让我们减轻那些已经通过了我们负责任扩展政策中概述的 CBRN 能力阈值的模型的越狱风险1。” 句式冗长且难懂,CBRN 需要解释。
- “Constitutional Classifiers” 需要翻译,且在第一次出现时需要给出英文原文。
- “来自人类红队测试的结果” 句式不自然。
- “红队测试” 需要解释。
- “漏洞赏金计划” 需要解释。
- “183 名活跃的2名参与者” 数字使用不当。
- “高达 15,000 美元的金钱奖励” 句式不自然。
- “尽管它对越狱具有鲁棒性,但这个原型系统有一些问题:它拒绝了太多无害的查询,并且运行成本很高。具有这两个问题的系统可能更安全,但也可能不实用。从那时起,我们改进了我们的系统,以实现类似水平的鲁棒性,同时大大减少了这些问题。” 句式略微冗长。
- “来自自动评估的结果” 句式不自然。
- “我们运行了一组自动评估,其中我们合成了 10,000 个越狱提示,包括许多对当前 LLMs 最有效的攻击,以及旨在规避分类器保障措施的攻击。” 句式略微冗长。
- “误差线表示使用二项比例标准误差在渐近正态假设下计算的 95% 置信区间。” 太过专业,需要解释。
- “同时,我们的 Constitutional Classifiers 并没有显著增加对无害用户查询的过度拒绝率:使用分类器,Claude 的拒绝率略有增加 (0.38%),但这在 5,000 个对话的随机样本中没有统计学意义。” 句式略微冗长。
- “它是如何工作的” 句式不自然。
- “Constitutional AI” 需要翻译,且在第一次出现时需要给出英文原文。
- “这两种技术都使用一个宪法:模型应该遵守的原则列表。” 句式不自然,“宪法”需要解释。
- “在 Constitutional Classifiers 的情况下,这些原则定义了允许和不允许的内容类别 (例如,允许芥末的配方,但不允许芥子气的配方)。” 句式不自然。
- “我们扩充这些提示和完成,以确保列表的多样性和多样性:这包括将它们翻译成不同的语言,并将它们转换为已知越狱的风格。” 句式略微冗长。
- “训练和实施 Constitutional Classifiers” 句式不自然。
- “局限性” 标题下的内容句式略微冗长。
- “Constitutional Classifiers 可能无法阻止每一个通用越狱,尽管我们相信,即使是少数通过我们分类器的越狱,在使用保障措施时也需要更多的努力才能发现。” 句式不自然。
- “未来也可能开发出对该系统有效的新越狱技术;因此,我们建议使用 互补的 防御。” 句式不自然。
- “Constitutional Classifiers 现场演示” 句式不自然。
- “想亲自尝试对 Claude 进行红队测试吗?” 句式不自然。
- “尽管 Constitutional Classifiers 技术非常灵活,可以适应任何主题,但我们选择专注于与化学武器相关的查询进行演示。” 句式略微冗长。
- “挑战用户尝试越狱我们的产品具有重要的安全目的” 句式不自然。
- “超出我们在论文中所做的测试” 句式不自然。
- “我们将在此帖子的更新中公布任何成功和演示的一般结果。” 句式不自然。
- “2025 年 2 月 5 日更新” 等更新部分句式不自然。
- “有关奖励和相关条件的完整详细信息,请访问 HackerOne。” 句式不自然。
- “我们现在正在努力确认结果并发送奖励;我们将在适当的时候提供我们从演示中学到的内容的完整更新。” 句式不自然。
- “致谢” 部分的句式需要调整得更自然。
- “如果您有兴趣解决诸如越狱鲁棒性之类的问题或与模型保障措施相关的其他问题,我们目前正在招聘 研究工程师 / 科学家,我们很乐意看到您的申请。” 句式略微冗长。
意译
本文由 简悦 SimpRead 转码, 原文地址 www.anthropic.com
Anthropic 的一篇论文,介绍了一种保护大语言模型 (LLM) 免受越狱攻击的新方法
Anthropic Safeguards Research Team 的一篇 新论文 介绍了一种可以抵御 AI 模型通用越狱攻击的方法。该方法的一个原型版本在经过数千小时的人工红队测试后,对通用型越狱攻击展现出强大的鲁棒性,不过也存在过度拒绝率较高和计算开销大的问题。改进后的版本在合成评估中达到了类似的鲁棒性,同时将误拒绝率降低了 0.38%,并适度增加了计算成本。
大语言模型接受过大量的安全训练,以避免产生有害的输出。例如,我们训练 Claude 拒绝回答与制造生物或化学武器有关的用户提问。
然而,模型仍然容易受到 越狱 (jailbreak) 攻击:这些攻击旨在绕过模型的安全防护,迫使它们产生有害的回复。有些越狱攻击会使用 非常长的提示 来“淹没”模型; 另一些则会改变 输入的样式,例如使用不寻常的大小写 (uSiNg uNuSuAl cApItALiZaTiOn)。 从历史上看,越狱攻击一直难以检测和阻止。 尽管这类攻击 早在 10 多年前 就已被发现,但据我们所知,目前还没有完全可靠的深度学习模型被应用到实际生产中。
我们正在开发更好的越狱防御机制,以便在未来可以安全地部署功能更强大的模型。根据我们的 负责任的扩展政策,只要我们能通过适当的安全保障将风险降低到可接受的水平,就可以部署这些模型——但越狱攻击允许用户绕过这些保障。我们特别希望,一个由宪法分类器 (Constitutional Classifiers) 防御的系统,能够帮助我们降低那些已超过 CBRN(化学、生物、放射性、核)能力阈值的模型的越狱风险,该阈值已在我们的“负责任的扩展政策”中列出。
在 我们的新论文 中,我们描述了一个基于 宪法分类器 (Constitutional Classifiers) 的系统,它可以保护模型免受越狱攻击。这些宪法分类器 (Constitutional Classifiers) 是利用合成生成的数据训练而成的输入和输出分类器,它们可以过滤掉绝大多数的越狱攻击,同时将过度拒绝的情况降至最低,并且不会带来巨大的计算开销。
人工红队测试结果
我们进行了两个主要类别的测试,以评估宪法分类器 (Constitutional Classifiers) 的有效性。
首先,我们开发了该系统的原型版本,用于识别和阻止与化学、生物、放射性和核危害相关的特定科学知识。然后,我们邀请了一些独立的越狱攻击者参与一项 漏洞赏金计划 (bug-bounty program,一种通过奖励来鼓励人们发现并报告软件漏洞的计划),让他们对系统进行“红队测试”(即在实验条件下尝试攻破系统,以测试其鲁棒性)。
具体来说,我们给他们提供了一份包含十个“禁用”问题的清单,他们的任务是运用任何他们认为有效的越狱技巧,让我们的一个当前模型 (本例中为 Claude 3.5 Sonnet,2024 年 6 月版),在原型宪法分类器 (Constitutional Classifiers) 的保护下,回答所有的问题。只有当模型对 所有 问题都给出了详细的回答,我们才认为这是一次成功的“通用”越狱攻击。
在为期两个月的实验中,183 位活跃的参与者总共花费了超过 3000 小时的时间来尝试对模型进行越狱攻击。如果他们能发现通用的越狱方法,将获得最高 15,000 美元的奖励。尽管投入了大量精力,但没有任何一位参与者能够仅通过一次越狱攻击就让模型回答全部十个禁用问题——也就是说,没有人发现通用的越狱方法。
尽管这个原型系统对越狱攻击具有很强的鲁棒性,但也存在一些问题:它会拒绝过多的无害查询,并且运行成本很高。一个存在这两个问题的系统或许更安全,但可能并不实用。自那时起,我们对系统进行了改进,在大幅降低这些问题的同时,实现了类似水平的鲁棒性。
自动化评估结果
我们进行了一系列自动化评估,合成了 10,000 个越狱提示,其中包括许多目前对大语言模型 (LLMs) 最有效的攻击,以及专门设计用来绕过分类器保护的攻击。我们使用这些提示测试了受宪法分类器 (Constitutional Classifiers) 保护的 Claude 3.5 Sonnet (2024 年 10 月版) 和一个没有分类器保护的 Claude 版本。
在没有防御分类器的基准情况下,越狱成功率高达 86%——这意味着 Claude 自身只阻止了 14% 的高级越狱尝试。然而,在使用宪法分类器 (Constitutional Classifiers) 保护 Claude 后,情况得到了显著改善:越狱成功率降至 4.4%,这意味着超过 95% 的越狱尝试都被拒绝。
自动化评估结果。对于所有图表,数值越低越好。(a) 在受宪法分类器 (Constitutional Classifiers) 保护的系统中,越狱成功率要低得多;(b) 在 Claude.ai 的免费版和专业版的实际使用中,使用宪法分类器 (Constitutional Classifiers) 时,系统的拒绝率并没有显著提高;(c) 使用宪法分类器 (Constitutional Classifiers) 的系统,其相对计算成本仅略微增加。误差线代表在渐近正态假设下,使用二项比例标准误差计算的 95% 置信区间(误差线指统计学中用于表示数据不确定性或误差范围的线段)。
与此同时,我们的宪法分类器 (Constitutional Classifiers) 并没有显著增加对无害用户查询的过度拒绝率:在使用分类器的情况下,Claude 的拒绝率仅略微上升了 0.38%,在 5,000 个对话的随机抽样中,这一差异没有统计学意义。最后,计算成本比未受保护的模型略高 (23.7%)。随着我们对这项技术的不断改进,我们也在努力进一步降低误拒绝率和计算成本。
总的来说,我们的自动化分析发现,更新后的宪法分类器 (Constitutional Classifiers) 系统显著提高了 AI 模型抵御越狱攻击的鲁棒性——而且只需增加极少的额外成本。
工作原理
宪法分类器 (Constitutional Classifiers) 的工作原理与 宪法 AI (Constitutional AI) 类似,后者是我们 用于对齐 Claude 的另一种技术。这两种技术都使用一部“宪法”:一份模型应该遵守的原则清单。在宪法分类器 (Constitutional Classifiers) 中,这些原则定义了允许和禁止的内容类别 (例如,允许提供普通芥末的配方,但不允许提供芥子气的配方)。
在 Claude 的帮助下,我们利用这部“宪法”生成了大量的合成提示和合成模型回复,覆盖所有内容类别。我们对这些提示和回复进行了扩充,以确保列表的多样性:包括将它们翻译成不同的语言,以及将它们的风格转换成已知的越狱攻击样式。
宪法分类器 (Constitutional Classifiers) 的训练与实施。(a) 生成一部“宪法”,明确有害和无害的类别;(b) 以“宪法”为基础,生成大量的合成提示和回复,并进一步扩充 (改变风格和语言),形成训练集;(c) 利用该训练集训练分类器,并将其用作模型保障措施,以检测和阻止有害内容。
然后,我们使用这些合成数据来训练输入和输出分类器,以便根据给定的“宪法”标记 (并阻止) 潜在的有害内容。为了尽可能减少过度拒绝 (即,将无害内容错误地标记为有害),我们还使用一组由承包商生成的良性查询来训练分类器。
局限性
宪法分类器 (Constitutional Classifiers) 可能无法阻止所有的通用越狱攻击,尽管我们相信,即使是少数能够绕过我们分类器的越狱攻击,在安全保障措施启用时,也需要付出更多的努力才能被发现。未来也可能会出现针对该系统的新型越狱技术;因此,我们建议同时采用 互补的 防御措施。不过,用于训练分类器的“宪法”可以快速调整,以应对新出现的攻击。
完整论文 包含了关于宪法分类器 (Constitutional Classifiers) 方法以及分类器本身的全部细节。
宪法分类器 (Constitutional Classifiers) 现场演示
想亲自尝试对 Claude 进行红队测试吗?我们邀请您体验 我们的宪法分类器 (Constitutional Classifiers) 防御系统的演示,并尝试对使用我们新技术保护的 Claude 3.5 Sonnet 版本进行越狱攻击。[2025 年 2 月 10 日更新:演示现已结束。 详情请见下文]。
尽管宪法分类器 (Constitutional Classifiers) 技术非常灵活,可以适用于任何主题,但本次演示中,我们选择重点关注与化学武器相关的查询。
让用户尝试对我们的产品进行越狱攻击,具有重要的安全意义:我们希望在真实环境下对系统进行压力测试,这超出了我们在论文中所做的测试。这有助于我们收集更多数据,并在未来将该方法部署到生产系统之前,进一步提高其鲁棒性。
演示 将于 2025 年 2 月 3 日 至 2025 年 2 月 10 日 开放。其中包含一个反馈表,您可以通过该表与我们联系,报告任何成功的越狱攻击,并了解我们的 负责任的披露政策,我们希望参与者遵守该政策。我们将在本文的更新中公布所有成功的案例以及演示的总体结果。
*2025 年 2 月 5 日更新:我们现在为成功越狱我们系统的参与者提供奖金。第一位通过我们越狱演示全部八个关卡的人将获得 10,000 美元。第一位使用通用越狱策略通过全部八个关卡的人将获得 20,000 美元。有关奖励和相关条件的完整详情,请访问 HackerOne。
**2025 年 2 月 10 日更新:现场越狱演示现已结束。我们非常感谢众多参与者尝试对模型进行越狱攻击,并向挑战赛的获胜者表示祝贺。我们正在确认结果并发送奖励;我们将在适当的时候提供一份完整的更新,介绍我们从演示中学到的经验。
致谢
感谢 HackerOne 对我们的漏洞赏金计划的支持,该计划旨在对我们的原型系统进行红队测试。同时感谢 Haize Labs、Gray Swan 以及 英国 AI 安全研究所 对我们系统的其他原型版本进行的红队测试。